Causal Video Generation as a Policy
TL;DR
We recreate the Direct Video Action Model (DVA) introduced by Rhoda AI, collecting 16.8M frame-action pairs of a diffusion policy playing in the PushT environment, and training from scratch a causal video model and inverse dynamics model to predict future frames and actions, respectively. Importantly, the causal video model acts as the policy, and over the course of training implicitly learns the behavior of the diffusion policy, essentially "dreaming" forward the future state of the environment.
Recently, Rhoda AI introduced the Direct Video Action Model and demonstrated its practical use in a generalist robotic system. DVA is interesting in both its generality (hence freedom to scale) and interpretability (you can "watch" dreams before they are turned into actions). Our goal was to practically replicate and validate the DVA in a short time-frame and on a low compute-budget. In this short technical report, we detail our open-source replication of the architecture, and our validation on the PushT environment.

In PushT, the policy controls a pointer, which a blue dot (subsequently referred to as the agent) follows non-instantaneously. The agent’s velocity towards the pointer is determined by its distance from the pointer (farther -> faster). The agent can push around a T-shaped object that is randomly initialized in the environment. The agent succeeds when the object superposes a non-moving green silhouette of itself with high overlap. We choose PushT because of its low visual complexity but non-trivial difficulty. In this environment, we do not explicitly condition on language, or specify the state as the location of the agent is entirely represented visually in the frame.
Without a source of conditioning, randomness in our data will lead to randomness in predicted frames and inferred actions. Hence, we use an existing strong diffusion policy and record the agent running this policy. The causal video model is then implicitly learning to imitate this policy during training. By launching parallel cloud environments, we're able to quickly collect ~2.6M frames of video, or ~72 hours at 10 frames per second of expert policy interacting in the environment. We also collect ~324 hours of random smooth movement and ~73 hours of heuristic goal-driven policy, for a total of ~16.8M frames. During training we transition from a 70/15/15 random/goal/expert split to a 0/20/80 and finally a 0/5/95 split as we shift from prioritizing learning basic dynamics to learning the optimal policy for PushT.1
Our encoder is a CNN, and produces (a) a token representation of the frame and (b) a spatial/feature representation of the frame. Our decoder is a U-Net trained with a flow-matching objective. There is a skip connection from the spatial representation to the decoder.2 In between, we add transformer blocks that perform self attention to the embeddings of past timesteps. In this sense, the DVA is strikingly similar to an autoregressive language model. For our video model we use a LLM-style pretraining loss where we compute loss at every position/frame, or what Rhoda describes as "context amortization". We train with a sequence length of 9 frames (7 prior frames, current frame, and next frame to calculate loss). Our IDM is a CNN, which takes in 2 frames and predicts the action to go from one to the other. In total, our combined total parameters is <30M parameters.3

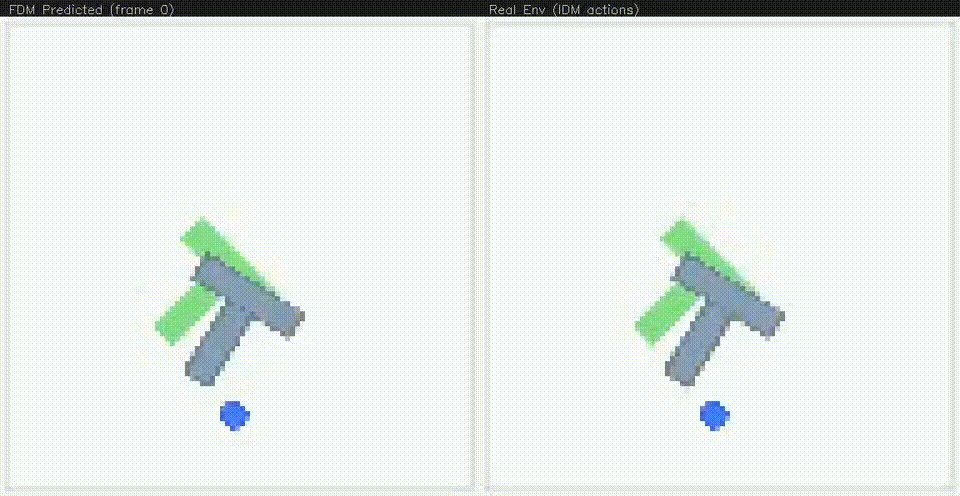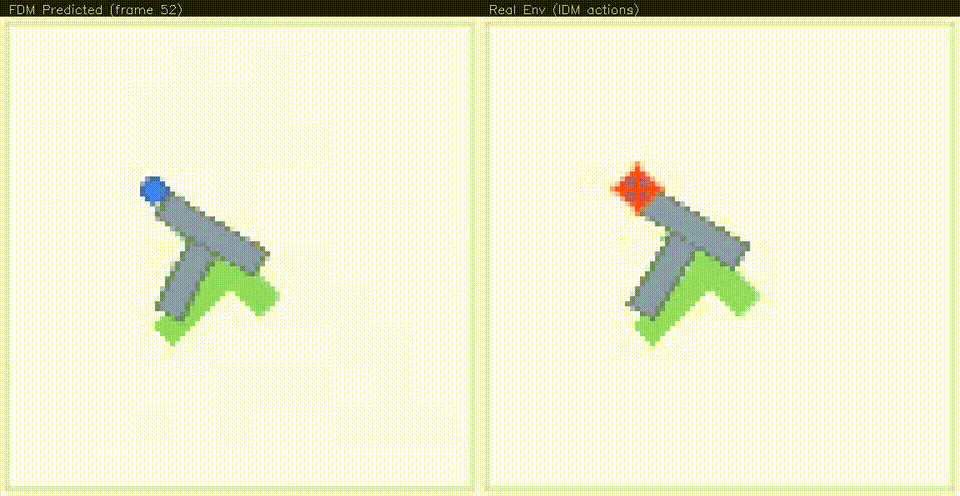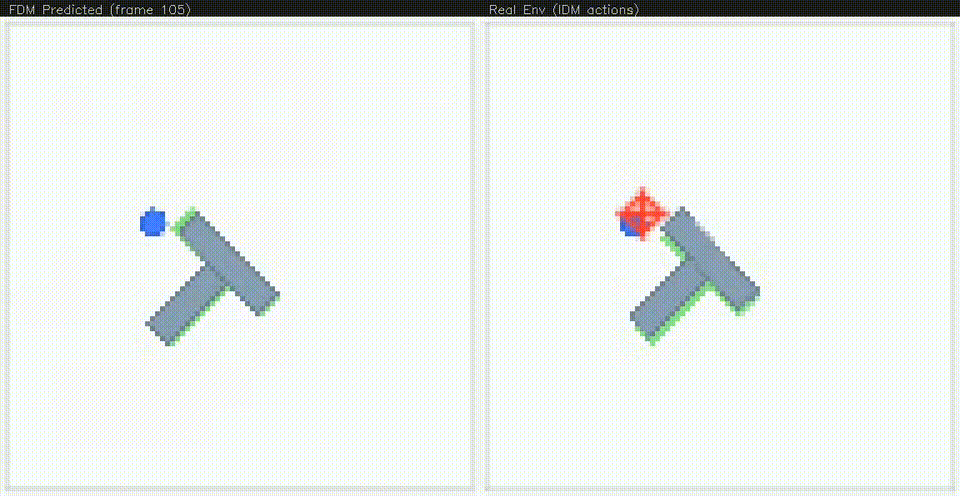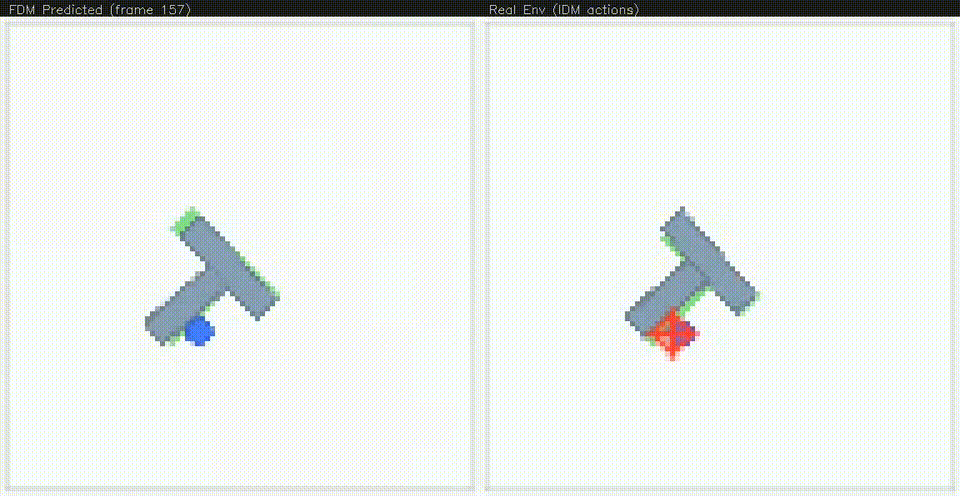
Early in training, the video model struggles to understand the dynamics of the system, often producing "disintegrating" T's. But after continued training, the model produces remarkably accurate autoregressive rollouts.
There are some exciting directions to take this further. There's low-hanging fruit remaining to optimizing architecture. And using the same data collection methods from parallelized simulations, DVAs can be trained for harder and more visually complex environments that require manipulation.
More ambitious projects to come :)
- We’ve open-sourced our dataset: https://huggingface.co/datasets/blankingout/pusht/tree/main/pusht_dataset ↑
- The skip connection is not strictly necessary for the model to work, but significantly speeds up decoder training by providing direct access to spatial features. ↑
- This can be further reduced by sharing encoder weights between the video model and the IDM, or by using a lighter decoder architecture. ↑