Scaling a No-Search Chess Engine
TL;DR
We distill 24.2M Stockfish (gold-standard chess engine) evaluations on positions drawn from the Lichess open database into transformers trained on varying compute budgets. Unlike Stockfish, this transformer doesn't do search. We perform data, size, and compute scaling law experiments in addition to a curriculum learning ablation on ascending evaluation depths. We also observe empirical support for Chinchilla scaling laws. You can play against the model at /chess.
We train a transformer to play chess. This project started with seeking to understand how chess engines like Stockfish worked, and then realizing that a no-search method could possibly be as strong as engines like Stockfish that use search. This isn't novel: DeepMind worked on this problem in a 2024 NeurIPS paper.12 Nevertheless, this is an interesting problem to do some cool experiments on, particularly recreating the neural scaling laws3 on a non-language task.
Loss. The input is a 70-token board representation: 64 square tokens, 1 side-to-move token, 4 castling tokens, and an en-passant token. The final representation is mean-pooled over tokens, which then goes into separate move, promotion, and value heads. The move head is a 4096-way (64²) square-to-square classification. We use a simple compound loss capturing move error, value error, and promotion error. Move loss comes from the cross entropy over the 4096 possible moves. Value loss comes from the MSE between the tanh of the model's value and the tanh of Stockfish's assessment of who is winning the game (scaled by 1/1000) to convert from Stockfish's unit of "centipawns" to a probability in either white or black's favor. Promotion loss comes from the cross entropy over 5 classes: no promotion, knight, bishop, rook, and queen. The promotion loss is calculated at all positions, not just promotion positions. Promotion error is weighted at 0.1, while move and value error are weighted equally at 1.0.
Architecture. We use SwiGLU FFN and pre-RMS Norm. The SwiGLU hidden dim is 8/3 of the embed dim rounded up to a multiple of 64. The exact architectures are listed below. Of important note is that the medium size model is chosen to be roughly Chinchilla optimal4 (~23 samples/param), while the small model (~250 samples/param) and large model (~3.2 samples/param) are overtrained and undertrained, respectively. The effect of this is commented later on in the results.
- Large: 256 embed dim, 8 layers, 8 attention heads; ~7.5M params
- Medium: 96 embed dim, 6 layers, 8 attention heads; ~1.1M params
- Small: 16 embed dim, 6 layers, 4 attention heads; ~0.096M params

We train on a single A100. We use a batch size of 256 and one-epoch training. Our base learning rate is 3e-4 with a cosine scheduler. We use depth-μP5 for learning rate scaling and the Muon optimizer6 for hidden layers. AdamW is used for embeddings, output heads, and norms. We apply a global norm clip of 1.0 every step. The test set is 100K Lichess positions from February 2026 evaluated at Stockfish depth 14.
We run the following experiments:
- A data scaling law
- A parameter scaling law
- A compute scaling law (approximated from the first two)
- Curriculum learning on ascending Stockfish move depth from depth 14 → 16 vs. random data mix.
For the curriculum learning experiment, the depth split was as follows:
- Depth 12: 2,718,767 samples (11.24%)
- Depth 14: 21,022,718 samples (86.91%)
- Depth 16: 446,397 samples (1.85%)
Results and Commentary.
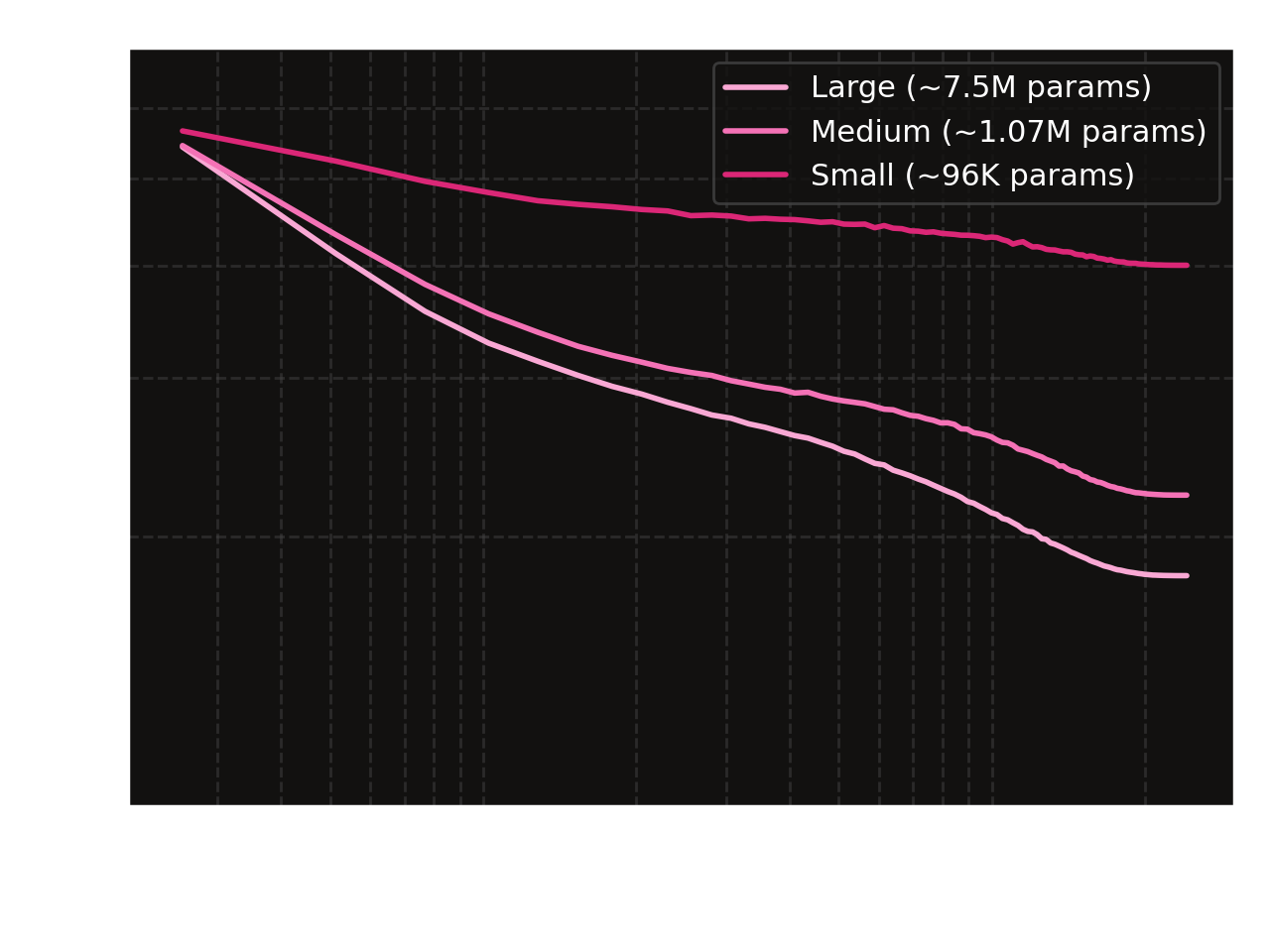
We observe that the data scaling law holds nicely across model sizes.
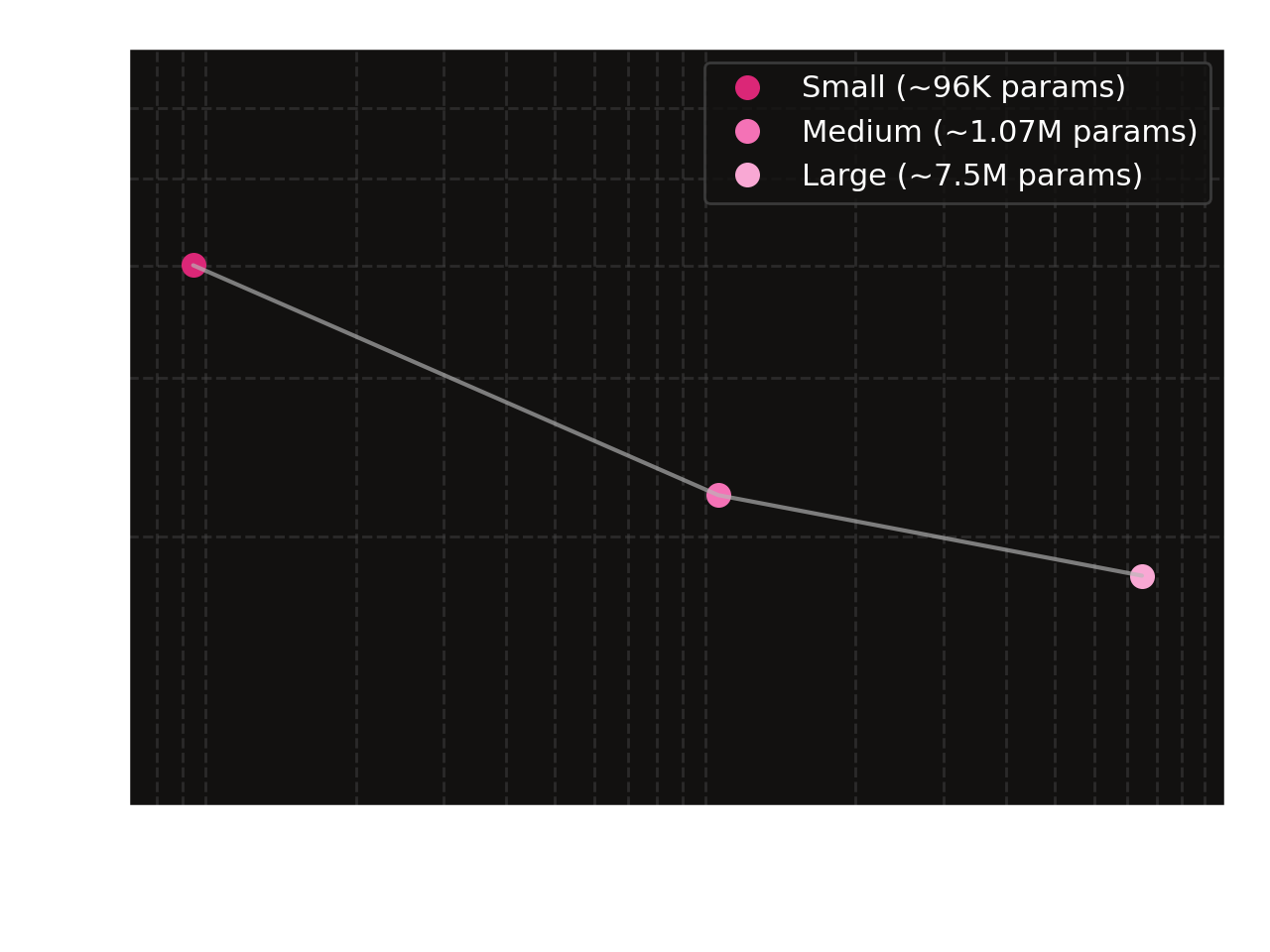
Plotting the final test loss for each model size, we see the parameter scaling law also holds.
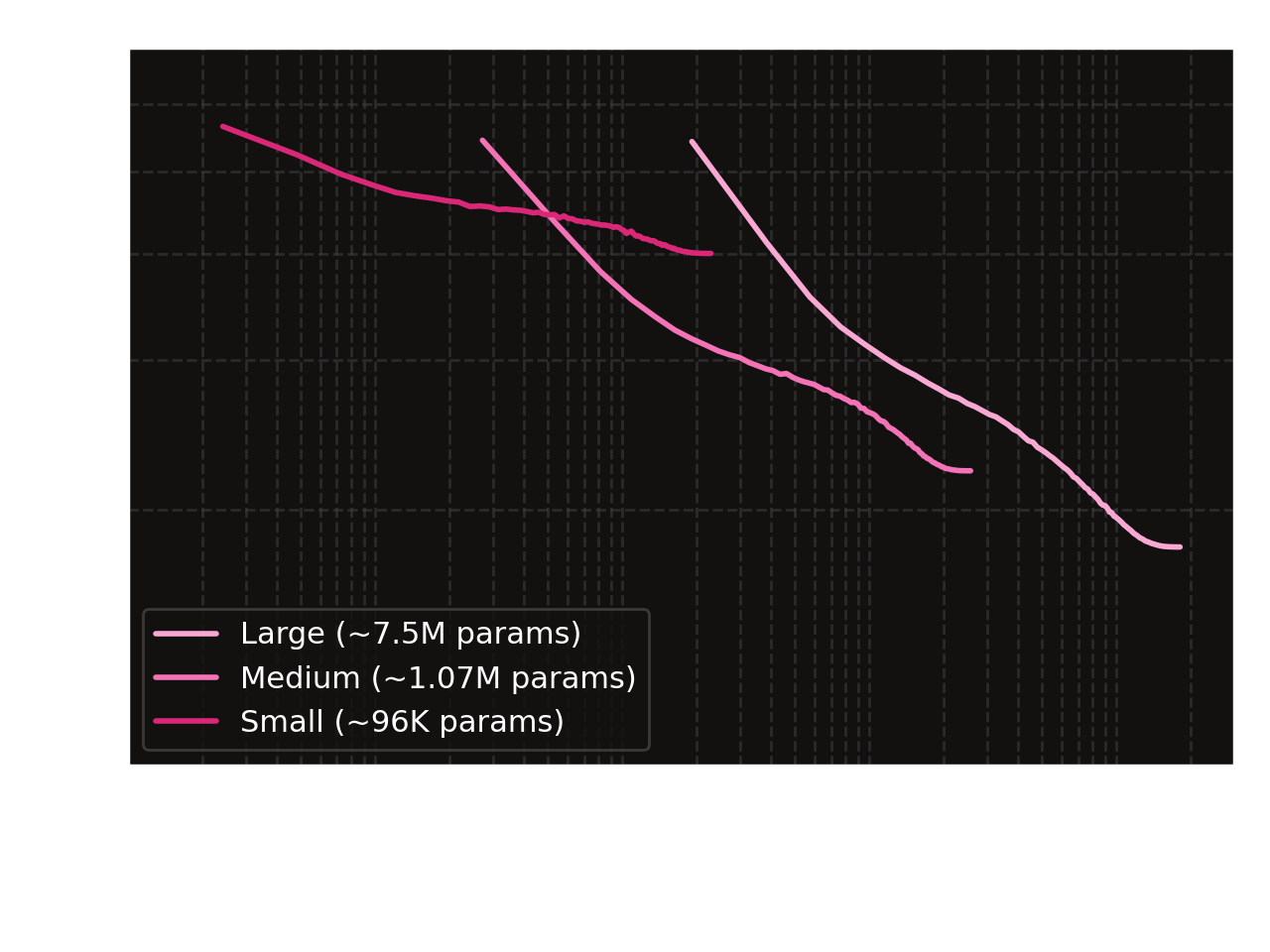
The compute scaling law (roughly approximated by multiplying parameter count by samples seen) also holds.
Very interestingly, these results also empirically support the Chinchilla scaling laws. The small model is far over chinchilla optimal (overtrained relative to param count), while the medium param model is roughly optimal and the large model is under chinchilla optimal. The fully-trained medium size model is pareto-optimal: it reaches close to the undertrained large size model's test loss on a OOM less compute budget.
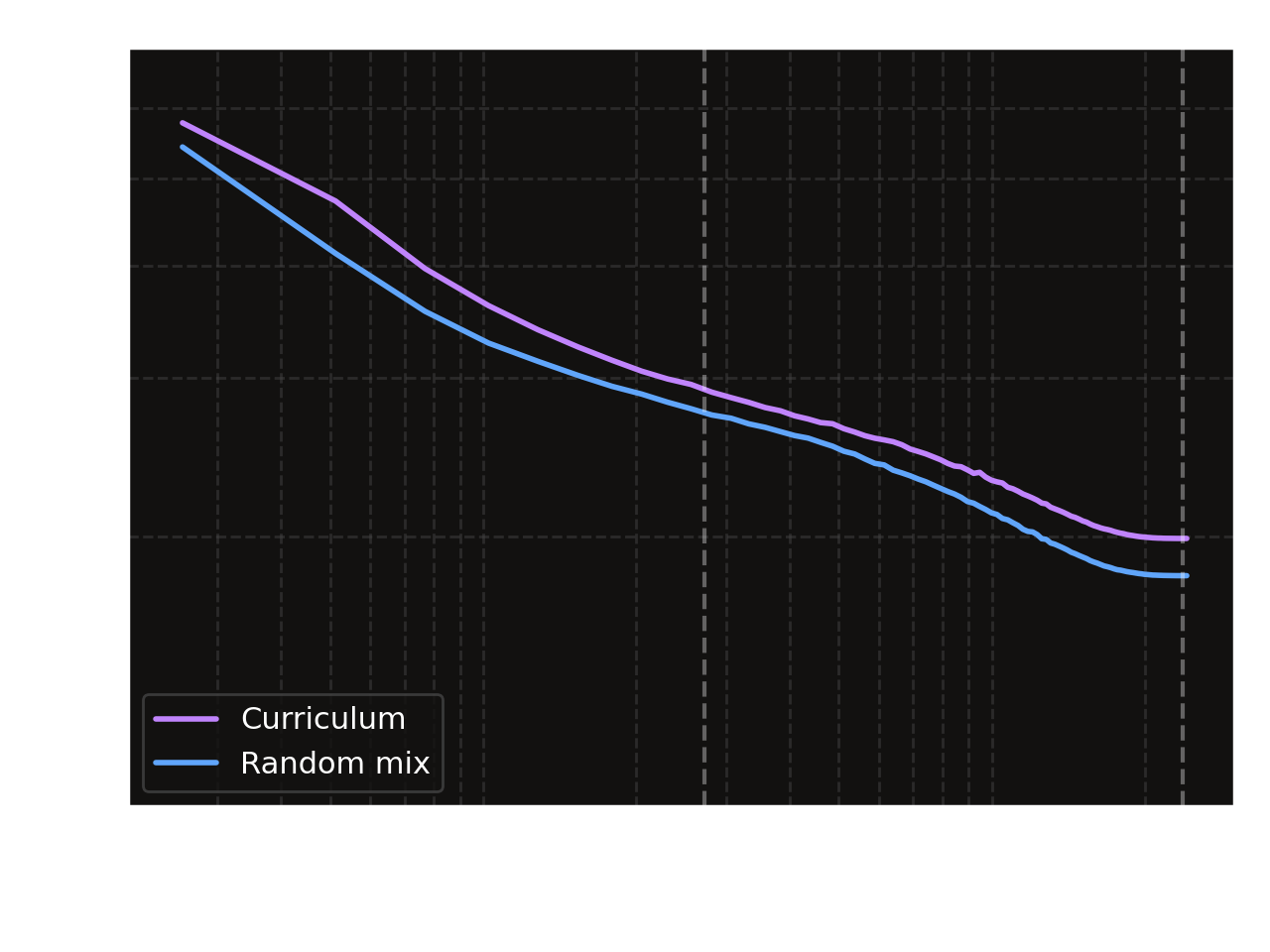
Curriculum learning on ascending Stockfish evaluation depth doesn't outperform training on a random shuffle of the dataset. Because of the relative scarcity of depth 16 data (2% of the training dataset), it may be fair to assume a negligible effect of depth 16 positions on the outcome of the experiment. This result could best be interpreted as "not exposing the model to higher quality data earlier in training has non-recoverable effects."
Closing.
- This was really fun.
- The scaling laws are real! And they work across domains. It's something that deserves continued regard. Observing Chinchilla optimality was particularly satisfying.
- You can play against the model at /chess.
More exciting work to come!
Thank you to Divij Motwani and Ashray Gupta for reading a draft of this post.
- Ruoss et al., "Grandmaster-Level Chess Without Search," NeurIPS 2024. ↑
- Autotelic (Adjective): An autotelic work of art or activity exists for its own purpose and not for any other reason. ↑
- Kaplan et al., "Scaling Laws for Neural Language Models," 2020. ↑
- Hoffmann et al., "Training Compute-Optimal Large Language Models," 2022. ↑
- Bordelon, Noci, Li, Hanin, Pehlevan, "Depth-μP: A Depthwise Parametrization for Feature Learning in Deep Neural Networks," 2023. ↑
- Keller Jordan, "Muon: An optimizer for hidden layers in neural networks," 2024. ↑